
들어가기 전
Object Detection은 이미지에서 객체 위치를 찾고, 객체 클래스를 분류하는 문제를 말한다.

객체가 위치한 영역을 표시한 박스를 bounding box라고 하며, 줄여서 bbox라고 부른다. bbox는 좌측 상단 좌표 & 가로/세로 길이로 나타낼 수 있다. 이렇게 객체가 위치한 부분을 RoI, Region of Interest라고 한다.

bbox를 찾는 대표적인 방법으로 Sliding window와 Selective search가 있다.
Sliding window는 고정 크기의 박스를 계속 움직여가며 객체 위치를 찾는다. 모든 영역을 탐색하면 윈도우 크기를 변경해 가며 같은 작업을 반복한다.

윈도우 안에 객체가 있으면 1, 없으면 0이 나온다.
Selective search는 색상, 질감, 영역 크기 등을 이용해 segmentation을 진행한다. 그리고 bottom-up 방식으로 유사한 영역을 합쳐가며 객체를 찾는다.

여러 bbox가 생성되면서 겹치는 영역이 발생한다. IoU는 두 box가 얼마나 겹치는가, 즉 교집합 영역 비율을 의미한다.

$IoU=\cfrac{Area\ of\ Overlap}{Area\ of\ Union}$
마지막으로 CNN과 Feature map에 대해 모른다면 아래 글을 참고하자.
CNN 이미지 분류 (MNIST 예제)
기본적인 CNN 모델을 만들기 위해 필요한 개념들을 정리하였다. 2D Convolution Convolution은 합성곱 연산이다. CNN 모델에서 이미지 특징을 추출하는 과정이 바로 합성곱 연산이다. Input: 입력은 (h, w) 크
denev6.tistory.com
Fast R-CNN
Fast R-CNN은 이름 그대로 R-CNN의 단점을 개선하며 등장했다. 가장 큰 특징은 end-to-end로 학습이 가능하다는 점이다. *R-CNN은 CNN + SVM(Support Vector Machine)을 연결해 파이프라인을 만들었다. 따라서 두 모델이 파라미터를 공유하지 못했다.
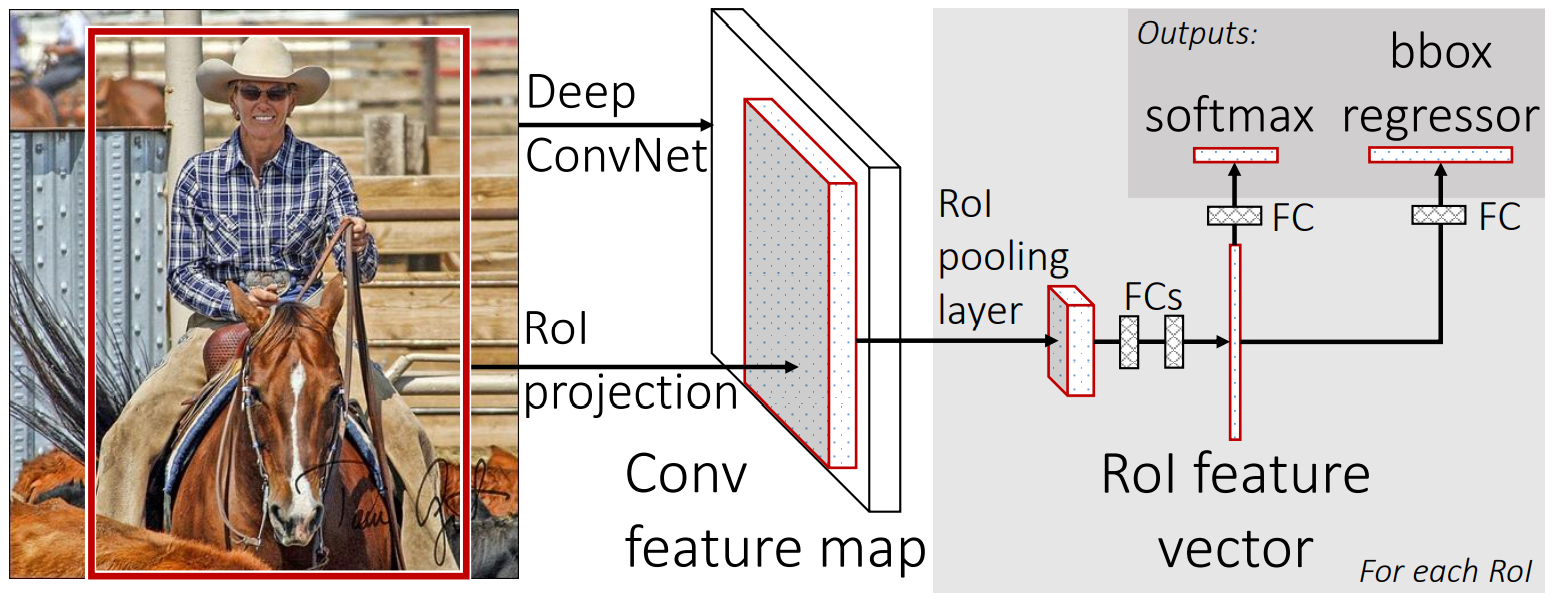
Selective search를 통해 RoI를 찾은 후, 전체 이미지와 RoI를 모델에 입력한다. 전체 이미지는 CNN을 통과해 feature map을 얻는다. 중간에 Rol Pooling과 Fully connected layer를 거쳐 출력층으로 간다. 마지막 출력층은 각각 softmax와 bbox-regressor로 객체 분류와 위치 탐색을 독립된 층에서 해결한다.
softmax 층은 bbox 안에 탐지된 객체의 클래스를 예측한다. 다시 말해 bbox 안에 있는 객체가 비행기인지, 버스인지, 말인지 분류하는 층이다. bbox regressor는 selective search를 통해 찾은 bbox를 정답(ground truth)에 가깝게 보정한다. 좌측 상단 좌표 & 가로/세로 길이를 이용해 regression 한다.
RoI Pooling
RoI Pooling은 feature map에서 RoI 영역에 대해 max pooling하는 과정을 말한다. 고정된 크기의 feature vector를 얻는 것이 목적이다. 아래 그림에서 결과는 H * W 크기를 가진다.

과정을 살펴보면, CNN을 통해 나온 feature map에 입력으로 받은 RoI를 투영시킨다. 이후 (h/H) * (w/W) 크기를 가지는 여러 개의 Grid로 feature map을 쪼갠다. 그리고 grid에서 max pooling을 통해 결과를 얻는다. pooling 된 feature vector는 Fully Connected layer를 거쳐 각 출력층에서 계산된다.
Multi-task Loss
Fast R-CNN은 다른 두 출력층에서 나온 정보를 조합해 Loss를 계산한다.
$L(p,u,t^u,u)=L_{cls}(p,u)+\lambda[u\ge 1]L_{loc}(t^u,v)$
$L_{cls}(p,u)=-\log p_u$
$L_{loc}(t^u,v)=\sum_{i\in\{x,y,w,h\}}smooth_{L1}(t^u_i-v_i)$
$p=(p_0, ..., p_K)$는 softmax를 거쳐 나온 예측 레이블이다. $t^k=(t_x^k,t_y^k,t_w^k,t_h^k)$는 bbox regression을 통해 나온 offset이다. $[u\ge 1]$은 $u\ge 1$일 때 1, 그 외에는 0으로 계산된다. 마지막으로 $\lambda$는 두 Loss의 균형을 잡는 파라미터로 논문에서는 $\lambda=1$을 사용했다.
Faster R-CNN
Fast R-CNN에서 RoI를 찾는 과정인 selective search는 CPU 위에서 이루어지기 때문에 병목 현상이 있다. 그래서 Faster R-CNN에서는 RPN을 이용해 CNN 수준에서 효율적으로 연산을 처리한다. 그 외 구조는 Fast R-CNN와 유사하다.
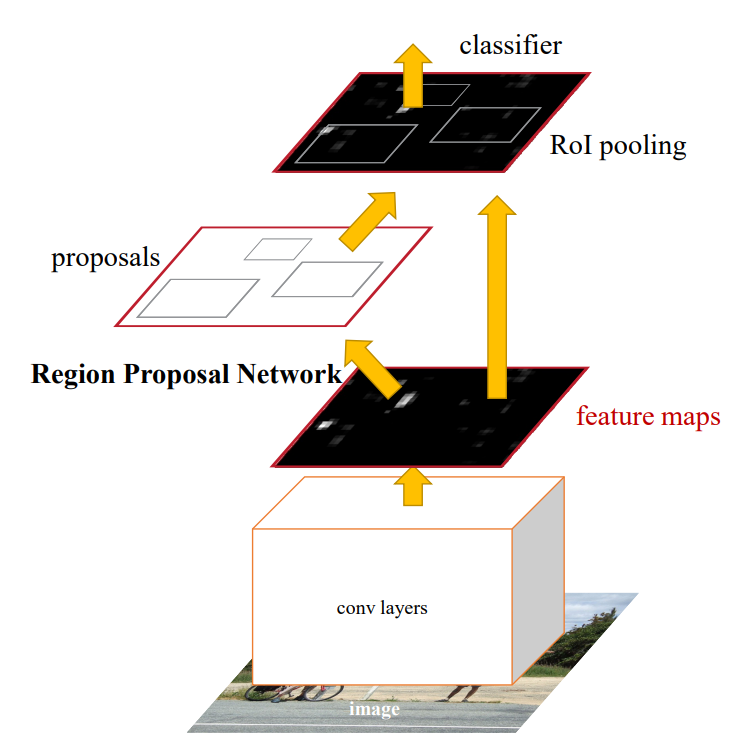
RPN
RPN, Region Proposal Network는 CNN의 feature map을 입력받은 후, sliding window를 통해 RoI(object proposals)를 찾는다.

이때 n * n 크기의 window를 sliding 하는데, 논문에서는 그림처럼 n=3을 사용했다. 3x3 conv layer를 거친 window는 작은 차원으로 매핑된다 (ZF: 256, VGG: 512). 참고로 feature map 크기를 유지하기 위해 padding을 사용한다. intermediate layer를 통과한 값은 1x1 conv를 거친다. 이 과정을 그림에서는 cls layer와 reg layer로 표현했다.
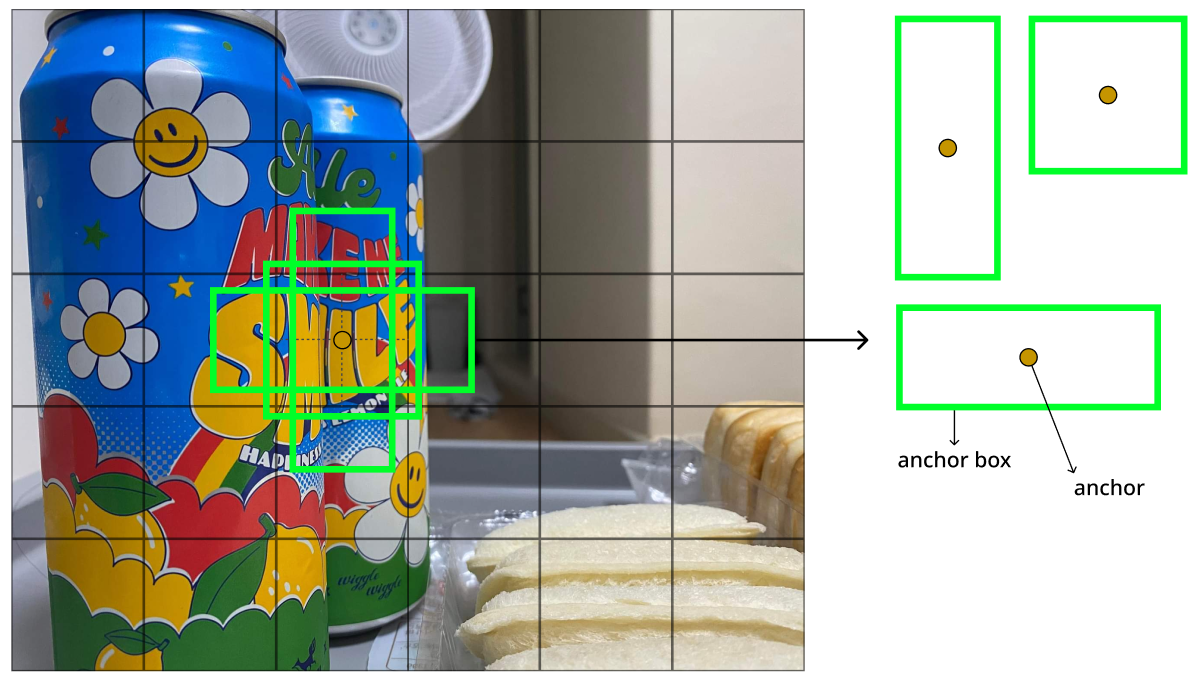
그리고 각 sliding window에 대해 anchor를 사용한다. anchor는 sliding window의 중심을 뜻한다. 이 anchor를 중심으로 여러 anchor box를 사용해 RoI를 찾는다. 논문에서는 3종류의 크기(scale)와 3종류의 비율(aspect ratio)을 가진 anchor box를 사용해 결론적으로 총 9종류의 anchor box를 사용한다 (k=9). 따라서 분류(cls) 층은 window 안에 객체가 있는지 여부만 판별하기 때문에 2k, bbox reg 층은 (x, y, w, h) 4개 정보를 가지기 때문에 4k가 된다.
| feature map 크기 | N x N x 256 |
| cls 출력 크기 | N x N x 2 x 9 |
| reg 출력 크기 | N x N x 4 x 9 |
Faster R-CNN에 대한 자세한 내용은 별도의 글로 다루겠다.