
Attention을 이해하기 위해 seq2seq에 대한 이해가 필요하다. Encoder/Decoder에 대해 모른다면 아래 글을 참고하자.
https://denev6.tistory.com/entry/Encoder-Decoder
RNN 개념과 Encoder-Decoder 구조
순환 모델 이해하기 RNN: Recurrent Neural Network은 순환 신경망으로 순서가 있는 sequence 데이터를 학습하는 데 사용한다. 단일 RNN 층을 보면 은닉층($h$)이 순환하며 이전 상태의 정보를 가져간다. 즉,
denev6.tistory.com
Attention이란?
Attention을 대략적으로 설명하면 아래와 같다.
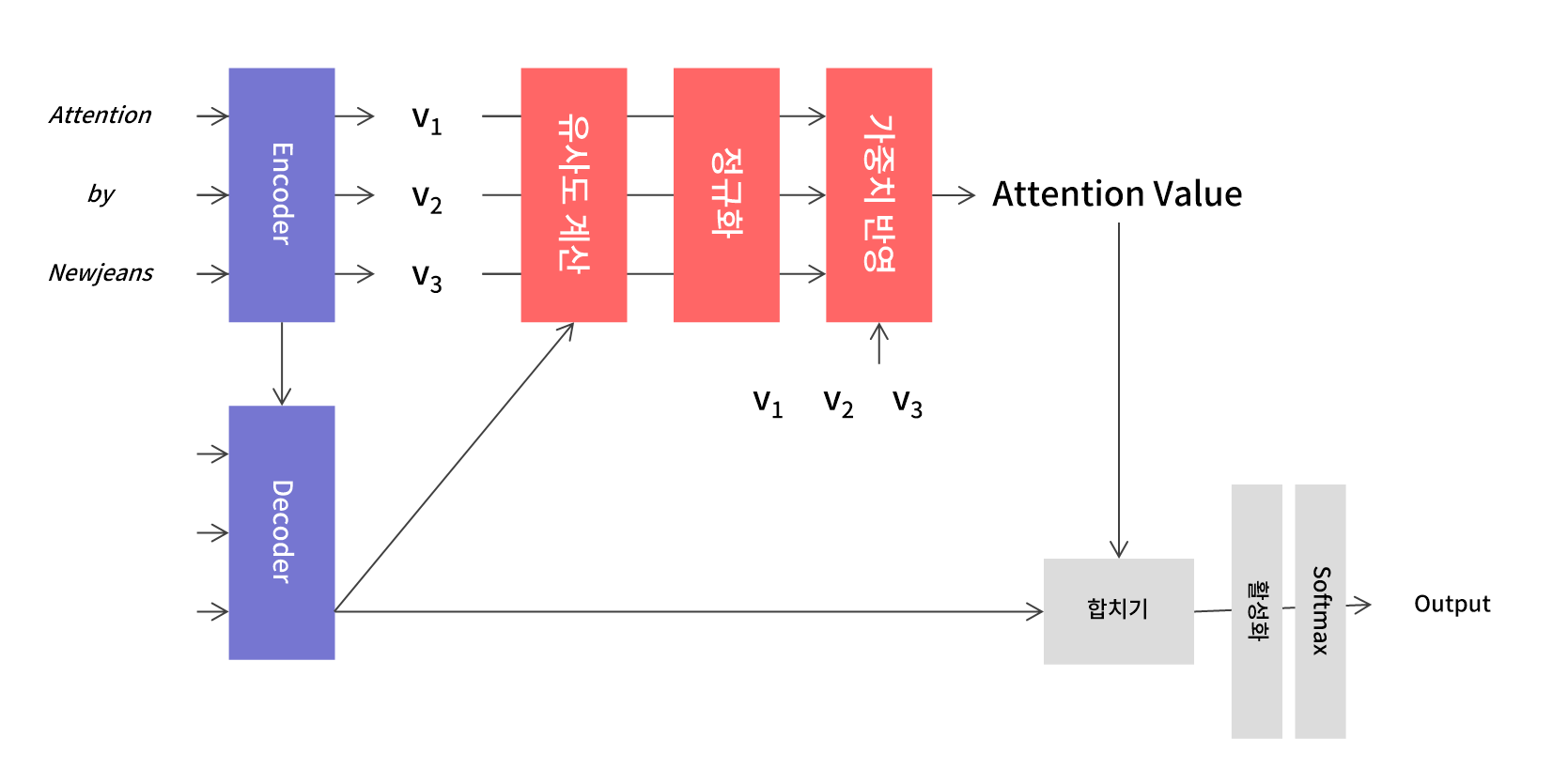
- Encoder를 거쳐 맥락을 담고 있는 벡터를 계산한다.
- 벡터와 Decoder 출력 사이의 유사도를 계산한다. 이를 통해 각 벡터가 얼마나 중요한지를 알 수 있다.
- 정규화된 유사도를 각 벡터에 곱해 중요한 정보에 집중(attention)할 수 있도록 한다.
- 가중치가 반영된 Attention Value와 Decoder 출력을 합쳐 출력층으로 보낸다.
쉽게 말해 각 벡터의 중요도를 계산해 상대적으로 더 중요한 정보를 더 많이 반영하는 구조다.
Query, Key, Value
Attention은 일반적으로 아래 식으로 표현된다.
$Attetion Value = Attention(Q, K, V)$
여기서 Q, K, V는 각각 Query, Key, Value를 의미한다.

- Query: t 시점 Decoder 셀에서의 은닉 상태(hidden state)
- Key: 모든 시점 Encoder 셀의 은닉 상태
- Value: 모든 시점 Encoder 셀의 은닉 상태
여기서 Key와 Value가 같은 값이 아닌가 의문이 들 수 있다. Key와 Value는 같은 값이 맞다. 다만 Key는 가중치를 계산하기 위해 사용되며, Value는 계산된 가중치가 반영되는 값이다. 역할 차이라고 볼 수 있다.
Dot-Product Attention
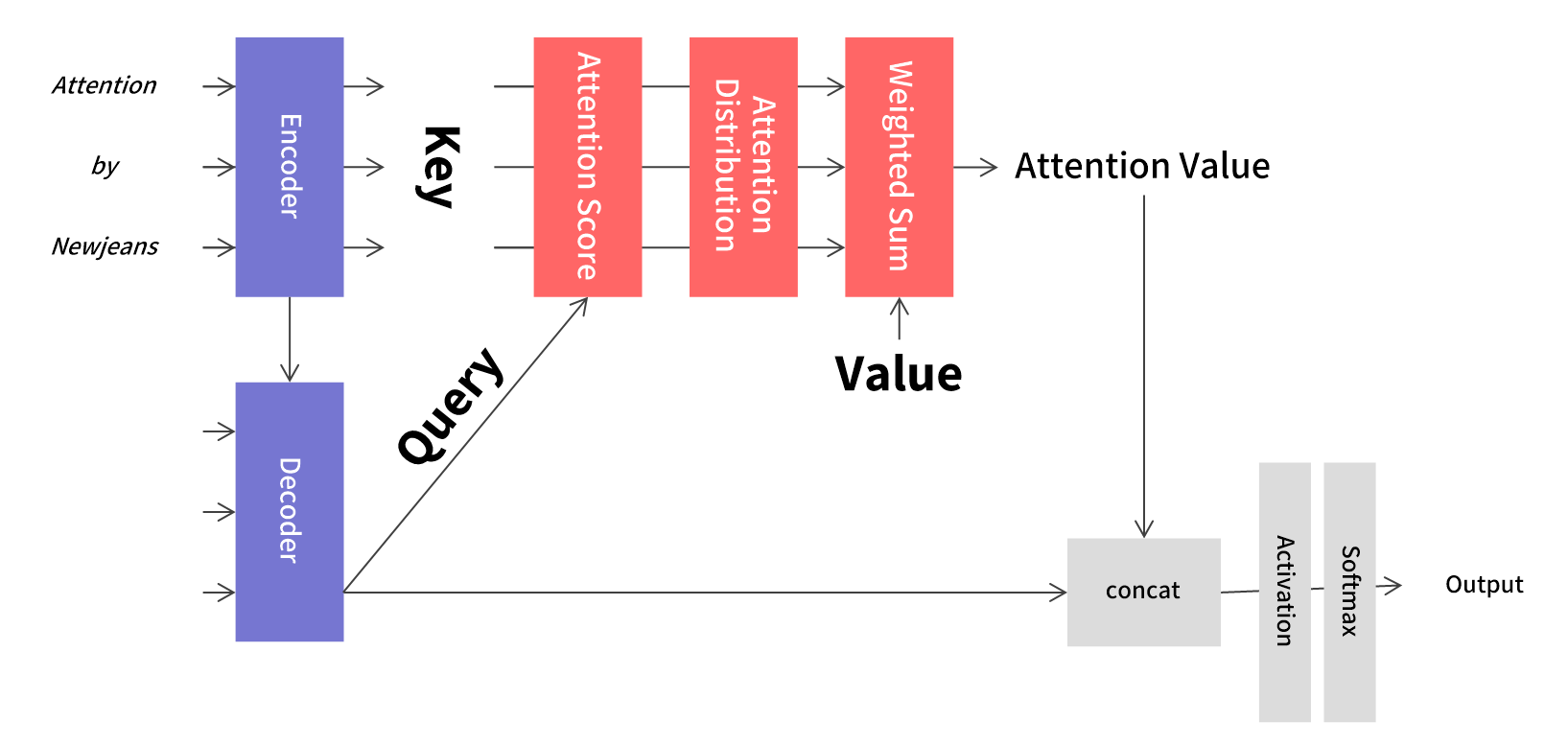
Attention Score & Distribution
Attention Score는 Query와 Key 사이의 유사도를 의미한다.
$Score(q_t, k_i)=q_t^Tk_i$
특정 시점 t에서 score는 아래와 같은 모습을 가진다.
$e^t=[q_t^Tk_1,...,q_t^Tk_N]$
Query와 Key의 유사도를 바로 Value에 반영하기에는 값이 일정하지 않다. 따라서 Softmax를 통해 정규화를 거친다.
$a^t=softmax(e^t)$
Attention Value
각 벡터 간 유사도를 계산했으니 Value에 가중합을 반영해 Attention Value를 구한다.
$a_t=\sum_{i=1}^N a_i^tv_i$
가중합을 통해 Attention Value인 $a_t$를 구했다.
Concat & Activate
Attention Value와 Decoder 출력을 연결해 최종 출력층으로 내보낸다. 아래 식은 활성화 함수로 tanh를 사용한 예시다.

$s_t=tanh(W_c[a_t;h_t]+b_c)$
$output=softmax(W_ys_t+b_y)$
Scale Dot-Product Attention
Dot-Product Attention은 Query와 Key의 점곱을 통해 score를 계산했다. Scale Dot-Product Attention은 점곱을 계산한 후 scaling하는 과정이 추가된다. $\sqrt{d_k}$는 key의 dimension을 의미한다.
$score(Q,K)=\cfrac{QK^T}{\sqrt{d_k}}$
$Distribution=softmax(\cfrac{QK^T}{\sqrt{d_k}})\ast V$
Dot-Product를 계속해서 유사도를 계산한다고 표현했다. 그 이유는 Cosine Similarity를 보면 알 수 있다. 코사인 유사도는 두 벡터의 L2 norm 곱으로 나누어 유사도를 구한다.
$cos(\theta)=\cfrac{A\cdot B}{scaling}$
이는 Scale Dot-Product에서 scaling하는 과정과 비슷하다. 자세한 내용은 별도의 글로 다루겠다.
그 외에도 score를 계산하는 방법에 따라 general, concat, location-base 등 다양한 attention이 존재한다.