
순환 모델 이해하기
RNN: Recurrent Neural Network은 순환 신경망으로 순서가 있는 sequence 데이터를 학습하는 데 사용한다.
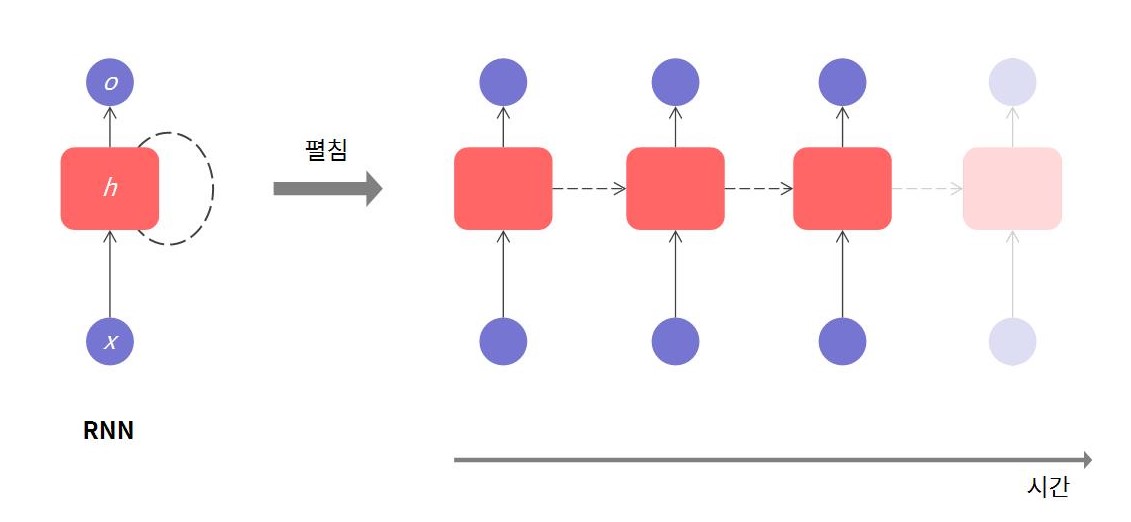
단일 RNN 층을 보면 은닉층($h$)이 순환하며 이전 상태의 정보를 가져간다. 즉, 반복되는 은닉층은 시간에 따른 맥락을 저장한다.
Multi-layer

RNN을 여러 층으로 쌓으면 위와 같은 형태가 된다.
연산 과정
$t$는 time step이다. $t-1$은 $t$ 바로 이전 상태를 의미한다.

먼저 RNN은 입력 2개를 받는다.
- 외부 입력($x$)
- $t-1$ 시점의 은닉층 정보($h^{t-1}$)
$t$ 시점 은닉층($h^t$)을 구하는 과정이다.
$z_h^t=W_{xh}x^t+W_{hh}h^{t-1}+b_h$
$h^t=\phi_h (z_h^t)$
각 가중치를 선형으로 계산한 후 활성화 함수를 거친다. $h^t$는 $t+1$ 시점 은닉층($h^{t+1}$)에 전달되어 다음 값을 예측하는 데 사용한다. $b$는 편향(bias), $\phi$는 활성화 함수를 의미한다.
$o^t=\phi_o (W_{ho}h^t+b_o)$
출력값($o$) 역시 선형으로 계산하고 활성화 함수를 거친다.
참고 (RNN 대안)
RNN은 긴 sequence를 이해하기 어렵다. 손실함수의 gradient를 계산하는 과정에서 Exploding Gradient 또는 Vanishing Gradient가 발생한다. 따라서 RNN보다 LSTM, GRU 등 모델이 흔하게 사용된다.
Seq2seq
Seq2seq: Sequence to sequence는 sequence를 입력받아 sequence를 출력하는 모델이다. 대표적으로 번역기가 있다. 예를 들어, "뉴진스의 하입보이요"라는 sequence를 받아 "Newjeans' Hypeboy"이라는 sequence를 출력한다.

Seq2seq는 크게 Encoder와 Decoder로 구성되어 있다.
Encoder
Encoder는 정보를 입력받아 하나의 백터로 정보를 압축시킨다. Encoder는 RNN으로 구성된다. "안녕 세계"(Hello world)라는 문장을 입력받으면 "안녕"이 첫 RNN에 입력되고, 그다음 "세계"가 입력된다.
이 글에서 RNN은 순환 신경망이라는 의미로 사용했다. 실제 Encoder는 성능 문제로 인해 RNN 모델 대신 LSTM이나 GRU를 사용한다.
Context Vector
Encoder를 거쳐 압축된 맥락 정보를 Context Vector라고 한다. 정확히는 Encoder RNN 마지막 시점 은닉층 벡터를 의미한다.
Decoder
Decoder는 압축된 context를 이용해 결과를 예측한다. Decoder도 RNN으로 구성되어 있다. 첫 RNN 은닉층 벡터로 Context Vector를 사용한다. 그리고 첫 RNN은 <sos>를 입력으로 받는다. 마지막 RNN은 <eos>를 출력한다. <sos>와 <eos>는 시작과 끝을 알리기 위해 약속된 벡터다.
예측과정

$t$ 시점의 RNN 입력은 $t-1$ 시점 출력이 된다. 앞에서 예측한 정보를 바탕으로 연속된 결과를 예측한다.
학습과정

Decoder 입력으로 정답 sequence를 입력한다. 이러한 학습 방법을 Teacher forcing이라고 한다. 예측과정에서 봤듯이 Decoder는 이전 RNN에서 예측한 결과를 바탕으로 다음 RNN 결과를 예측한다. 따라서 중간에 잘못된 출력이 발생하면 연쇄적으로 잘못된 출력을 만들게 된다. 따라서 정답 데이터를 입력해 정답에 가깝게 예측할 수 있도록 도와준다.
Encoder-Decoder를 이해하기 위해 RNN부터 살펴봤다. 실제 모델은 단어를 Embedding하는 과정부터 Decoder에서 Softmax를 거쳐 값을 예측하는 과정 등 일부 연산이 추가된다.