
Abstract
- 이전보다 더 깊은 모델을 학습
- 레이어 입력을 참고하도록 재구성
- residual network는 깊은 모델의 정확도를 올림
Introduction
vanishing/exploding gradient가 모델 수렴을 방해한다. 이는 normalized initialization과 intermediate normalization layers로 해결할 수 있다.
하지만 degradation 문제도 발생한다. 정확도가 낮아지지 않고 training error가 얕은 모델보다 크다.

본 연구는 deep residual learning framework로 degradation 문제를 해결했다.
Deep Residual Learning
Residual Learning
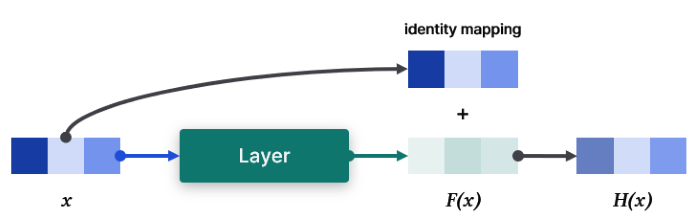
- layer 입력을 $x$라고 가정
- layer 출력을 $H(x)$라고 기대. (전체 모델이 아닌 layer 출력도 포함)
- 레이어가 $H(x)$ 대신 $F(x) := H(x)-x$를 학습하도록 함
- 원래 기대하는 출력은 $F(x) + x$로 도출
$H(x)$와 $F(x)$를 출력하는 모델이 같은 결과를 낼 거라고 생각할 수 있지만, 학습 난이도가 다르다.
레이어 출력인 $H(x)$는 $x$의 특징을 추출한 값이다. 따라서 $H(x)$는 $x$와 유사한 특징을 가진다고 볼 수 있다. 다시 말해, $H(x)$는 원본 복원(identity mapping) + 작은 변형(perturbation)으로 볼 수 있다. 이때 작은 변형을 $F(x)$로 표현한 것이다.
degradation 문제는 모델이 여러 비선형 layer를 거치면서 identity mapping이 힘들어지는 것으로 볼 수 있다. 여기서 residual learning을 사용하면 단순히 비선형 layer가 0으로 향하도록 만들어 identity mapping을 수행할 수 있다. 이 방식은 identity mapping을 새로운 함수로 학습시키는 것보다 쉽고, 레이어는 작은 변화($F$)를 찾는데 집중할 수 있다. 실제 학습된 residual function은 일반적으로 작은 반응을 보인다. (이후 "CIFAR-10 and Analysis"에서 다시 언급)
Identity Mapping by Shortcuts
$$\mathrm{y} = \mathcal{F}(\mathrm{x}, { W_i }) + \mathrm{x}$$
$\mathrm{x}$와 $\mathrm{y}$는 각각 입출력이며, $\mathcal{F}$는 학습할 residual mapping이다.
$\mathcal{F} + \mathrm{x}$는 shortcut connection과 element-wise addition으로 구현한다. shortcut은 특정 값이 레이어를 건너뛰는 것을 말한다. 덕분에 같은 파라미터의 plain 모델과 residual 모델을 한 번에 비교할 수 있다. (단순히 shortcut을 열고/닫고로 구현 가능하다.)
$$\mathrm{y} = \mathcal{F}(\mathrm{x}, { W_i }) + W_s \mathrm{x}$$
다른 방법으로 square matrix $W_s$를 이용해 차원을 맞춘다.
함수 $\mathcal{F}$는 2 ~ 3개 레이어를 사용해야 한다. 한 개만 사용하면 선형 레이어와 다를 것 없다. 또한 $\mathcal{F}$는 convolution 연산으로, element-wise 덧셈은 각 채널에 대해 진행한다.
Network Architectures
Plain Network: Baseline으로 VGG net을 사용한다. 대부분 convolution은 3 x 3 필터를 사용하며 아래 규칙을 따른다.
- feature map 크기와 같은 크기의 filter 사용
- feature map 크기가 절반이라면, filter 크기는 2배로 시간복잡도를 유지
stride를 2로 두어 직접적인 down-sampling을 시도한다. 마지막에 global average pooling과 1000-way softmax를 적용한다.

Residual Network: 위에서 소개한 baseline을 기반으로 shortcut을 추가한다. 차원이 증가했을 때는 2가지 옵션 중 하나를 사용한다.
A. zero paddingB. 1x1 convolution
두 옵션 모두 차원이 맞지 않아 down-sampling이 필요한 경우 stride를 2로 사용한다.
Implementation
이미지 짧은 쪽을 256 또는 480으로 샘플링한다. 224 x 224 랜덤 자르기 + 가로 뒤집기 + 픽셀 단위 빼기와 standard color augmentation를 적용한다. convolution + activation 뒤에는 정규화 진행한다. (AlexNet: "Data Augmentation"참고)
- SGD
- mini-batch: 256
- learning rate: 0.1 (error가 수렴하지 않을 때 10으로 나눔)
- 최대 $60\times 10^4$ iterations
- weight decay: 0.0001
- momentum: 0.9
테스트에는 10-crop testing(AlexNet 참고)과 여러 스케일의 이미지에 대한 점수 평균(VGG 참고)을 사용했다. 이미지 크기는 {224, 256, 384, 480, 640}이다.
스케일이 다른 이미지를 어떻게 학습시킬 수 있을까? Pytorch 공식 구현을 보면 AdaptiveAvgPool2d를 사용한다. Convolution 연산은 채널 크기만 맞다면 입력 크기가 달라도 문제 없이 연산할 수 있다. 하지만 Linear는 고정된 크기를 입력으로 받는다. 따라서 Pooling을 통해 고정된 크기로 변환시켜 Linear에 입력되도록 한다.
Experiments
ImageNet Classification
Plain Network를 확인했을 때 34-layer가 18-layer보다 높은 validation error를 보였다. 34-layer 학습 과정 내내 더 높은 training error를 보였다. 이는 vanishing gradient 때문으로 보이지는 않는다. 이 모델은 정규화를 진행했으며, 신호가 0이 아닌 분산을 가지도록 학습했다. 정규화를 통해 역전파에서도 gradient가 잘 넘어가는 것을 확인했다. 따라서 forward와 backward 모두 신호가 사라지는 문제는 없었다. (문제가 발생한 이유에 대해서는 후속 연구로 넘겼다.)
18-layer와 34-layer ResNet을 평가했으며, 옵션 A(zero-padding)를 사용한다. 크게 3가지 사실을 발견했다.
- Plain Net과는 반대로 34-layer가 18-layer보다 좋은 성능을 보였다. 오히려 34-layer가 유의미하게 낮은 training error를 보였다.
- Plain Net과 비교해 34-ResNet이 더 낮은 training error를 보였다.
- 레이어가 너무 깊지 않을 때(예: 18-layer) ResNet이 plain보다 빨리 수렴했다. ResNet은 초반 최적화가 쉬워 빠른 수렴 속도를 보였다.
차원이 같다면 parameter 학습이 없는 identity shortcut이 학습에 유리하다. 차원이 다른 경우(Eqn.2)에 대해서는 3가지 shortcut을 비교했다.
A: zero-paddingB: projection(차원이 증가할 때) + identity(그 외)C: projection
B는 A보다 약간 더 좋았다. 0으로 고정된 부분은 학습되지 않기 때문이라고 추측한다. C는 B보다 확실히 좋았으며 더 많은 파라미터를 사용했기 때문으로 보인다. 하지만 A/B/C의 차이는 작은 수준이며, projection shortcut이 반드시 필요하지는 않다. 따라서 본 연구는 C를 사용하지 않는다. 연산 시간과 복잡도를 줄이기 위해서다. 특히 identity shortcut은 아래 소개할 bottleneck 구조의 복잡성을 줄이는데 도움이 된다.
학습 시간 단축을 위해 Bottleneck 구조를 사용했다.

첫 1x1 conv는 차원을 압축(또는 유지)하고, 마지막 1x1 conv는 차원을 복원한다. 이 구조에서 projection을 사용하면 모델 복잡도가 커진다. 따라서 identity shortcut이 더 효율적이다.
34-layer ResNet에 2-layer 블록을 3-layer bottleneck으로 바꿔 50-layer ResNet을 만들었다. 같은 방식으로 {101, 152}-layer Resnet을 만들었다. {50, 101, 152}-Resnet은 34-ResNet보다 눈에 띄게 좋은 정확도를 보인다.
CIFAR-10 and Analysis
모델 별 layer 출력의 표준편차를 비교했다.

출력은 3x3 conv + 정규화 결과로, 비선형 함수(ReLU)를 거치기 전이다. ResNet이 Plain 모델보다 작은 반응을 보였다. 이는 residual 함수가 0과 가까운 값($\mathcal{F}$)을 낼 것이라는 가정을 증명한다. 또 레이어가 많을수록 각 레이어는 큰 변화를 보이지 않았다.
1202-layer는 110-layer와 비슷한 training error를 보였음에도 더 나쁜 결과를 냈다. 이는 데이터에 비해 큰 모델로 인해 overfitting이 발생한 것으로 추측한다. 이때는 maxout이나 dropout 같은 강한 regularization이 필요하다.