
이미지 segmentation에 대해 다루며, CNN을 활용한 FCN(Fullly Convolutional Network)을 중심으로 소개한다. FCN은 논문 "Fully Convolutional Networks for Semantic Segmentation"에서 소개되었다.
Image Segmentation

이미지 segmentation은 픽셀 단위로 객체 클래스를 분류하는 문제를 말한다. 이는 각 픽셀마다 이미지 분류 문제를 푸는 것과 같다. c개의 레이블이 있다면 배경(0)을 하나의 레이블로 두고 총 c+1개의 레이블로 분류하는 문제가 된다.

기존의 CNN classification 모델은 2차원 feature map을 1차원으로 압축해 결과를 출력한다. 만약 2차원 정보를 유지한 채로 분류를 진행한다면 어떨까? Linear 대신 CNN을 이용해 2차원 공간 정보를 유지할 수 있다. 이때 분류 결과로 나온 2차원 레이블은 각 픽셀의 레이블로 해석할 수 있다.
이 방법을 활용하면 사전학습된 AlexNet, VGG, ResNet 등 모델 파라미터를 특징 추출에 사용할 수 있다. 이러한 모델을 backbone이라고 한다.
(backbone): # ResNet 모델
(classifier): FCNHead(
(0): Conv2d(2048, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
(3): Dropout(p=0.1, inplace=False)
(4): Conv2d(512, 21, kernel_size=(1, 1), stride=(1, 1))
)위 예시는 픽셀을 20개 레이블(배경 포함 21개)로 분류하는 모델이다. 총 21개의 2차원 행렬이 출력되며, 각 행렬은 해당 레이블일 logit을 담고 있다.
Loss Function
Loss는 각 픽셀에 대해 계산한다. 단순히 Cross-entropy를 이용해 픽셀 간 차이를 구하면 된다. 논문에서 "per-pixel multinomial logistic loss"라는 문장이 등장하는데, 이는 Cross-entropy와 같은 표현이다.
Fully convolutional networks
Fully convolutional networks(FCN)은 대표적인 CNN 기반 segmentation 모델이다. 모델은 VGG를 backbone으로 사용했으며, upscaling과 skip connection 등을 기술을 적용했다.
Upscaling
일반적인 classification 모델은 down-scaling을 진행한다. 큰 영역부터 시작해 convolution layer를 지나며 feature map 크기가 작아진다. 예를 들어, 500x500 이미지를 입력하면, 10x10 feature map을 출력하는 식이다. backbone으로 사용한 VGG도 마찬가지다. 하지만 출력을 픽셀 단위로 매칭시키기 위해서는 입력 이미지와 출력 행렬의 크기가 같아야 한다. 500x500 이미지에 픽셀마다 레이블을 나눠주기 위해서는 500x500 행렬이 있어야 한다. 따라서 upscaling이 필요하다.
Upscaling은 bilinear interpolation과 de-convolution을 사용한다.
- Bilinear interpolation은 픽셀 간 거리를 계산해 빈 공간을 채우는 기법이다. 자세한 방법은 Blog: 양선형 보간법에서 설명한 적 있다.
- De-convolution은 크기를 키우는 convolution 연산으로, 기존 convolution과 동일하게 학습이 가능한 layer이다. "Transposed Convolution"라고 불린다.
기본으로 end-to-end 학습이 가능한 de-convolution을 사용하며, 마지막 upscaling에만 interpolation을 적용한다.
Skip connection
CNN 모델은 초반에 넓은(global) 영역에 대해 특징을 추출한다. 레이어가 깊어질수록 좁은(local) 영역에 대한 특징을 추출하게 된다. Skip connection은 넓은 영역의 특징과 좁은 영역의 특징을 결합하는 과정이다.
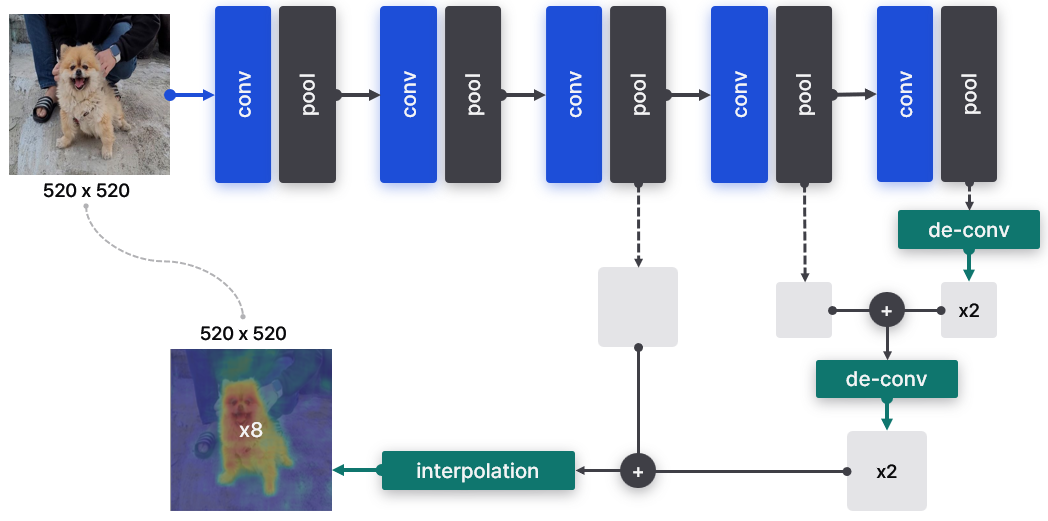
레이어마다 feature map 크기가 다르기 때문에 upscaling(de-convolution)을 진행하며 크기를 맞춰간다. 크기가 같아진 두 행렬은 원소별 덧셈을 통해 더해진다. 마지막으로 계산된 행렬을 원본 이미지와 같은 크기로 키우면 segmentation map이 완성된다.
Skip connection이 필수는 아니지만, 적용했을 때 약간의 성능 향상이 있었다고 논문에서 설명한다. 위 그림과 같이 총 3개의 feature map을 사용했을 때 가장 좋은 결과를 얻었다.
Torch-Vision
Torch-vision은 ResNet을 backbone으로 하는 FCN을 제공한다.
- Torch 문서: Pytorch: FCN
- 본문 코드: Github
from torchvision import models
weights = models.segmentation.FCN_ResNet50_Weights.DEFAULT
label_names = weights.meta["categories"]
model = models.segmentation.fcn_resnet50(weights=weights)Torch는 (원본 FCN과 달리) 두 종류의 출력을 가진다.
out: 추론을 위한 출력 (skip connection 없음)aux: 학습을 위한 skip connection을 적용한 출력
image_path = "dog1.jpg"
image_tensor = preprocess_image(image_path)
outputs = predict(image_tensor, model) # dict: {'out', 'aux'}따라서 모델 출력은 OrderedDict 타입으로 out과 aux라는 키를 가진다. inference를 위해서는 'out'을 사용한다.
scores = torch.softmax(output.squeeze(0), dim=0)
classes = scores.argmax(dim=0)
unique_classes = torch.unique(classes)- diningtable(11): 53.90
- dog(12): 95.35
- person(15): 91.52
- sofa(18): 55.33
출력을 확인해보면 dog(12)와 person(15)에 대해 강한 확신을 보인다. Segmentation 결과를 입력 이미지에 겹치면 직관적으로 이해할 수 있다.

- 좌측 이미지는 모델 출력에
softmax+argmax를 적용해 레이블만 시각화한 결과다. - 중앙 이미지는 좌측 label을 입력 이미지 위에 겹친 모습이다.
- 우측 이미지는 입력 이미지 위에 "dog" 레이블의 segmentation map을 출력한 결과다.