
문제 상황
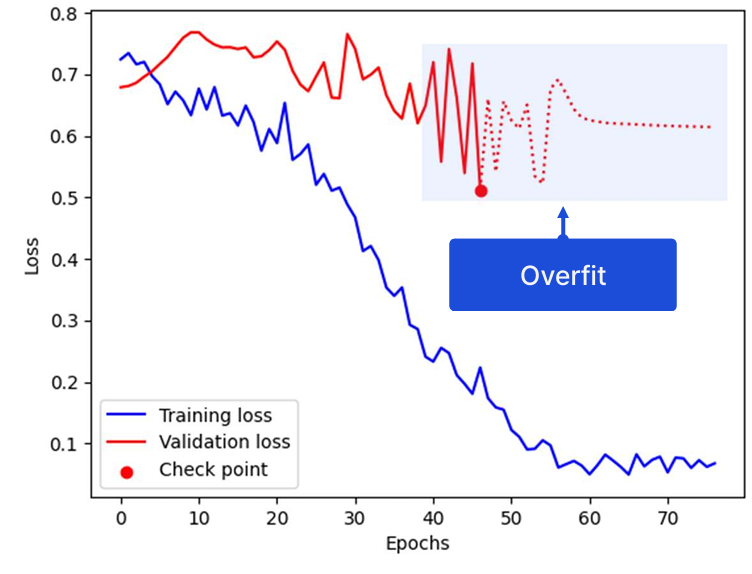
모델의 Training loss는 잘 수렴하지만 Validation loss가 크게 요동친다. 눈 감고 무시하기에는 너무 큰 문제다. 그래프를 통해 모델이 Overfit 되었다고 예측할 수 있다. Overfit 되었을 때 여러 방법을 시도해 볼 수 있다.
- 학습 파라미터 조정 (Learning rate, Dropout rate, weight decay 등)
- 데이터 증강 (또는 추가 수집)
데이터를 늘리는 것이 가장 효과적이지만 현실적으로 쉽지 않다. 이때 시도해 볼 수 있는 방법이 K-Fold Cross Validation이다. (이하 교차 검증)
Cross Validation
교차 검증은 데이터를 K개로 쪼갠 뒤, 번갈아가며 Training set과 Validation set으로 사용한다.

Subset으로 쪼갠 데이터를 모두 Training 또는 Validation으로 사용해 보고, Validation loss가 가장 낮은 모델을 선택한다. 다시 말해 가장 일반화가 잘 된 모델을 최종 모델로 선택하는 방식이다. 이렇게 하면 가진 데이터를 최대한으로 활용해 모델을 학습할 수 있다.
겹치기 않게 주의
이때 주의할 점은 각 모델을 독립적으로 학습시켜야 한다. 1번째 Fold로 학습한 모델은 2번째 학습에 영향을 주어서 안 된다. Data leakage 때문이다.
첫 번째 모델은 { 2, 3, 4, 5 }번} 번 데이터를 학습한 상태이다. 따라서 학습한 파라미터를 이용해 { 2, 3, 4, 5 } 번 데이터에 대한 Validation loss를 구하면 당연히 좋은 결과를 보인다. 마치 답지를 미리 학습시키고 시험을 보게하는 상황이다. 따라서 각 Fold는 독립적으로 학습시키며, 그중 가장 잘 일반화가 잘 된 모델을 최종 선택한다.
코드 구현
Scikit-learn의 KFold와 Pytorch의 Subset을 이용해 쉽게 구현할 수 있다.
from sklearn.model_selection import KFold
from torch.utils.data import Subset, DataLoader
k_folds = 5
kf = KFold(n_splits=k_folds, shuffle=True, random_state=42)
for fold, (train_idx, val_idx) in enumerate(kf.split(train_dataset), start=1):
# 데이터셋 나누기
train_dataset_fold = Subset(train_dataset, train_idx)
val_dataset_fold = Subset(train_dataset, val_idx)
train_loader = DataLoader(train_dataset_fold, batch_size=batch, shuffle=True)
val_loader = DataLoader(val_dataset_fold, batch_size=batch, shuffle=False)
# 모델, Optimizer 초기화
model = CNN()
optimizer = optim.Adam(model.parameters(), lr=1e-3)
# 학습
for i in range(epochs):
for batch_id, (data, label) in enumerate(train_loader, start=1):
output = model(data)
# 생략...데이터를 Subset으로 나누는 부분만 추가됐을 뿐, 나머지 학습 과정은 동일하다.
일반적으로 K=5를 많이 사용하며, 데이터가 적거나 머신러닝 모델을 학습할 때는 10까지 사용하기도 한다.