
Batch
학습을 위해 사용할 데이터가 너무 많을 때 한 번에 학습시키는데 비용이 많이 들기 때문에 여러 개의 그룹으로 나누어 학습한다. 이때 나누어진 그룹을 Batch라고 한다.
Batch Normaliztion
Batch Normalization은 layer를 통과할 때마다 데이터 분포가 달라지는 Internal Covariate Shift를 해결할 수 있다. 따라서 정규화를 통해 안정적으로 학습될 수 있도록 한다.
- 정규화
- 스케일링
정규화란 데이터의 분포를 N(0, 1)로 조정하는 과정이다.
다시 말해 평균을 0, 분산을 1로 조정하는 과정이다.
아래 그래프에서 초록색 그래프가 정규화된 그래프이다.
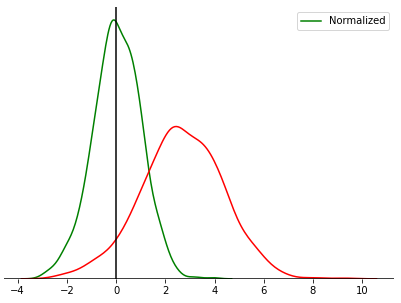
batch마다 분포가 다르기 때문에 정규화를 통해 일정하게 학습이 되도록 한다. 그렇기 때문에 정규화는 각각의 batch에 대하여 진행한다.
$x_{normalized}^i=\cfrac{x^i-\mu_B}{\sigma_B+\epsilon}\\
where \\
\mu_B=\cfrac{1}{m}\sum_i^m x^i\\
\sigma_B^2=\cfrac{1}{m}\sum_i^m(x^i-\mu_B)^2$
* 여기서 μ는 배치의 평균을 뜻하고, σ는 표준편차를 뜻한다. ϵ는 ZeroDivision을 막기 위해 사용하는 작은 값이다.
하지만 평균이 0이라는 것은 절반 정도의 데이터가 음수라는 것이다. 이러한 데이터를 활성화 함수에 넣으면 값이 모두 0이 되어 버리는 구간이 발생한다.
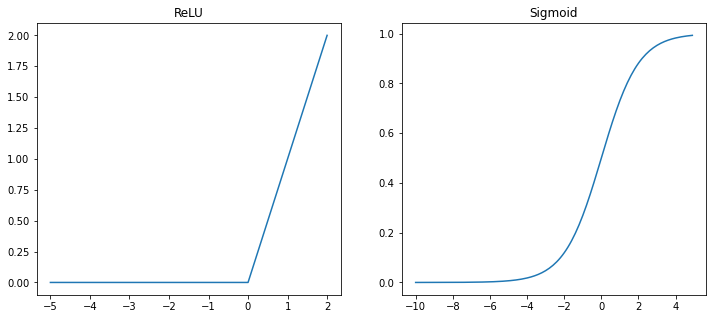
따라서 정규화된 값을 조정해야 한다.
$y^i=\gamma x_{normalized}^i+\beta$
γ와 β는 backpropagation을 통해 업데이트할 수 있다.
이후 test set에 대하여 예측을 진행할 때는 연산 효율을 위해 μ, σ, γ, β 값을 고정하여 사용한다.
pytorch: BatchNorm2d
from torch import nn
nn.BatchNorm2d(num_features)affine=True를 통해 γ, β를 학습할 수 있다. (Default: True)
tensorflow: BatchNormalization
import tensorflow as tf
tf.keras.layers.BatchNormalization()training=True를 통해 γ, β를 학습할 수 있다. (Default: False)